

日本アイ・ビー・エム(株)
Power Systems テクニカル・セールス
佐々木 幹雄
- CPWはスループット指標であり、レスポンスタイムを保証しない。
- 新システム移行でコア数が極端に減る場合、新モデルでCPUクロックが低下する場合、レスポンスタイムに留意したサイジングが必要(Tipsあり)
- 最新のIBM i パフォーマンス分析ツールPerformance Data InvestigatorはブラウザーGUI`で容易に深くパフォーマンス分析ができる。
CPUのマルチスレッド機能
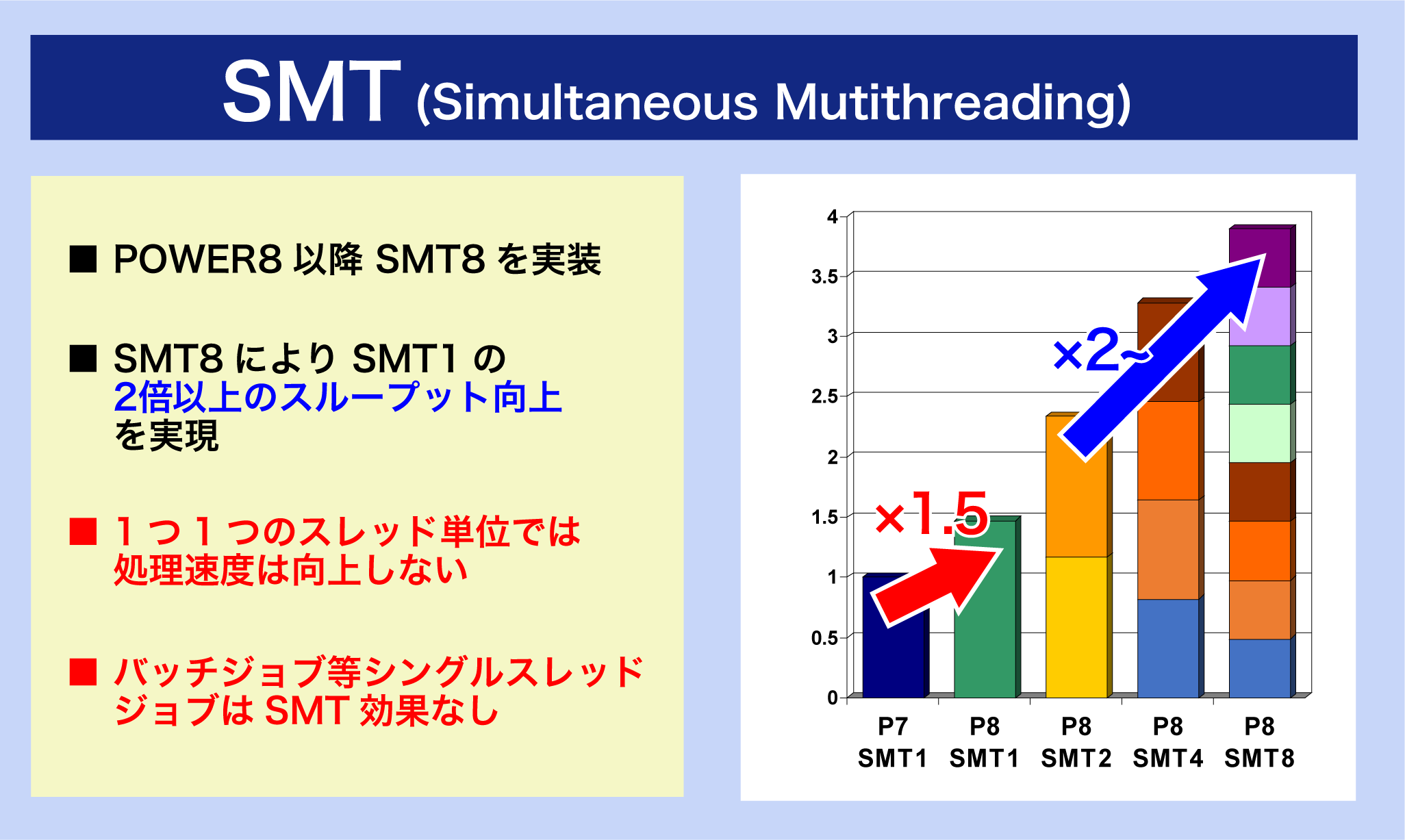
昨今のCPUは1つの物理CPUコア上で複数スレッドを同時処理する技術が実装されています。インテル社ではハイパースレッディングと呼ぶ技術で、POWERプロセッサーでは単にSMT(Simultaneous Multithreading)と称されます。POWER8以降はSMT8(1コアで8つのスレッドを同時実行可能)となっています。POWER8は、「SMT8を利用する事でSMT1(CPUのマルチスレッド機能を利用しない)の2倍以上のスループットを実現する」とされています。しかし、これは「個々の(スレッド単位での)処理速度がSMTを利用すると高速化される」、のとは異なることに注意が必要です。
SMT有無による個々のスレッドの処理時間への影響
ここで簡単なモデルでSMTの効果を見てみましょう。

SMT無しでは1つのスレッドの処理が完了するまでCPUの回路に空きがあっても他のスレッドは実行されません。青のスレッド1の実行が完了するまで7サイクル必要で、8サイクル目に次の赤のスレッド2が実行開始され…という様に1つずつジョブが実行され4つのスレッドが完了するために全部で29サイクル必要です。
対してSMT有りでは1つの物理コアで最大8つの命令を同時実行できるため、4つのスレッドをわずか8サイクルで完了できます。SMT有無を比較するとCPUの回路で処理が実行されていない白色のマス目の数の違いが歴然です。SMTとはこのようにできるだけCPUの回路を遊ばせない様にスレッドを詰め込むための機能という事ができます。図Aと図Bを比較すると4つのスレッドを完了するまでに29サイクルから8サイクルになった、すなわち29÷8で3倍以上も短時間で4つのスレッドが実行完了できたと言えます。このようにすべてのスレッドより短時間で実行完了した事をもってスループットが向上したという事が言えます。
ところで、図Aと図Bで青スレッド1、緑スレッド3、黄スレッド4の実行完了までのサイクルを比較すると、7サイクルから8サイクルに悪化しているのです。SMTはスループットを確実に向上させますが、一方で一つ一つのスレッドの処理時間(レスポンスタイム)は悪化させる可能性もあります。 システムの性能指標にはスループットとレスポンスタイムという二軸があるとご理解ください。

IBM i 性能指標(サイジング指標)CPWはスループット指標である
IBM i の性能指標はAS/400時代以来一貫してCPW(Commercial Processing Workload)で表されています。多くのIBM i ユーザーはCPWはスループットとレスポンスタイムの両方の指標だと考えているかもしれません。それはPOWER6辺りまでCPWの向上と同時に新しいCPUはクロックも前モデルより高速化されました。その結果CPWの向上はスループットとレスポンスタイム双方が向上となっていたのだと思われます。しかしPOWER7以降ではCPUクロックは前モデルより低下することもよく見られるようになりました。また、コア当りCPW値が劇的に向上したため、CPW値を同値に揃えてLPARへの割当コアを減らして新システムへ移行するす動きも出てきました。筆者の見聞した範囲での話となりますが、割当コア数を削減してシステム移行するとCPW値は増加していても、個々のジョブのレスポンスタイムが悪化する事例が複数見受けられました。
ですので改めて「CPWはスループット指標である」ことを再認識いただければと思います。

同じCPW値のシステムではスループットは近似しますが、レスポンスタイムは悪化するケースもありえる、ということをご理解ください。
IBM i のレスポンスタイムを考慮したサイジングTips
それでは、IBM iが稼働するPower Systemsのリプレースに際してレスポンスタイムが低下しない様なサイジングをすることは可能でしょうか?厳密な意味でのそれは(IBM i に限らず、ですが)かなりハードルが高く、IBMとしての公式なサイジングガイドは公開されていないようです。そこで代替として筆者個人と周囲の技術者で共有している簡便なサイジングTipsをご紹介しましょう。最初に一点、お断りさせて頂きますが以下のTipsは筆者個人の見解によるものであり、IBM公式のものではありません。このためSWMAなどのIBMサポートへの下記Tipsのお問い合わせは一切ご遠慮くださいますようお願い致します。

具体的な例で上記Tipsを確認してみましょう。
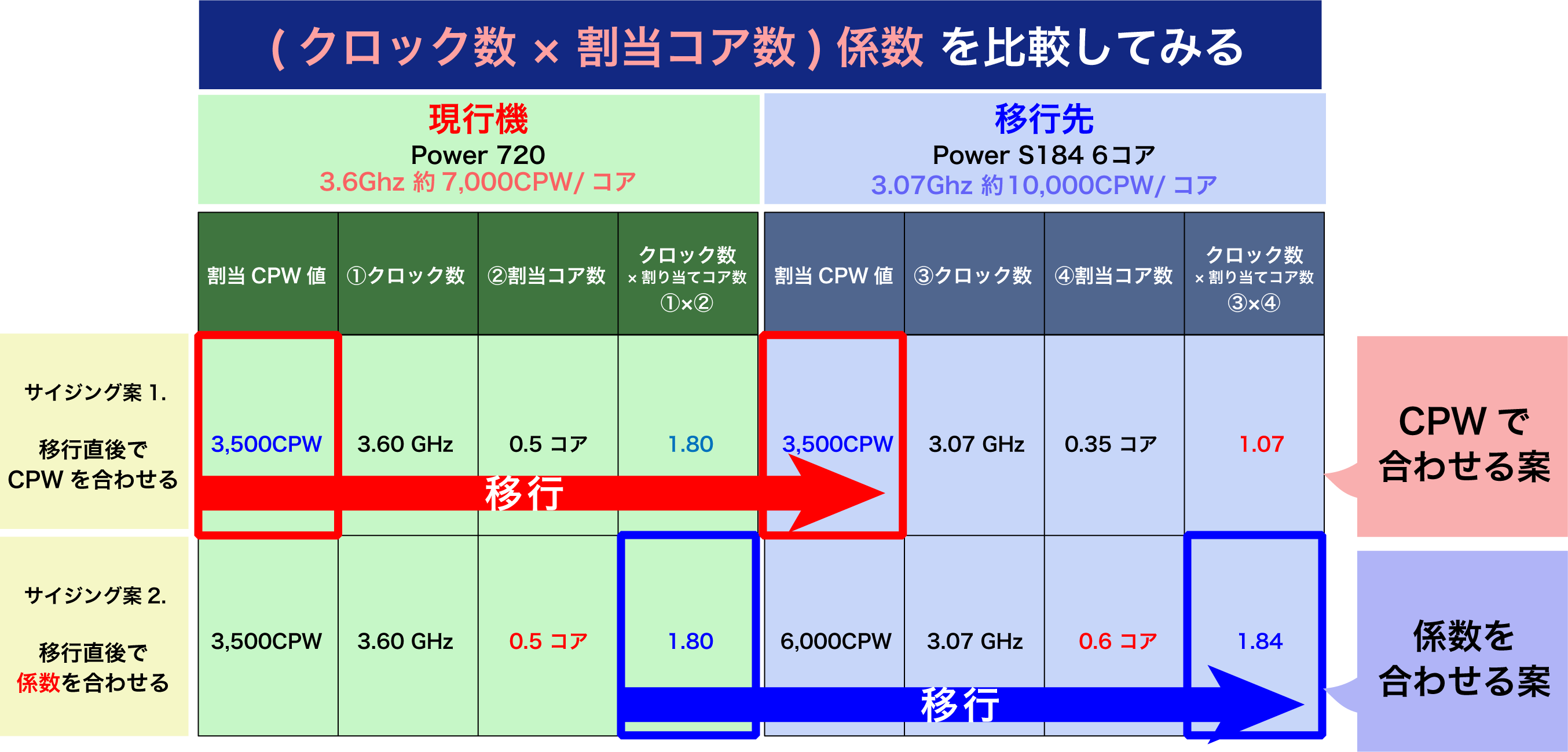
サイジング案1が従来よく見られたCPW値を合わせるサイジングの方法です。この例のシステムはPOWER7からPOWER8への移行例でコア当り性能が約1.4倍になるため割当コア数が0.5コアから0.35コアで賄える計算になります。この場合の移行前後の係数を比較すると1.80から1.07ととても小さくなっていることがわかります。このような移行のケースで、新システムでスループットは維持されるものの個々のトランザクションのレスポンスタイムが遅くなる現象が比較的顕著に観測されました。
サイジング案2は係数を移行前後で同値に合せる案です。移行前が1.80ですのでほほ同値の1.84となるようコアを0.6コア割当てています。新しいシステムに移行したにも関わらずコア数を増やさなければならない理由がCPUクロックの差になります。移行前=3.60GHzから移行後に3.07GHzに低下しているため係数を合わせるには0.6コア割り当てが必要になるのです。このサイジング案2のようにサイジングした移行システムでは筆者の知る限りレスポンスタイムの劣化は確認されていません。経験則的には移行後の係数が移行前と同値以上が望ましいのですが、費用その他制約上むつかしい場合はサイジング案2をベストケースとして色々な要件を勘案して可能な限り係数が近くなるようにサイジングすることをご検討ください。
IBM i の最新パフォーマンス分析ツール
AS/400時代からIBM i は非常にすぐれた(精緻な)パフォーマンス分析が可能でした。ただ、従来のパフォーマンス分析ツールの欠点を言えば専門家でないと使いこなせなかった点にあると思います。ところが、最新のIBM i では非常に簡単な手順で誰でも詳細なパフォーマンス分析ができるように改良されています。最も大きな要因はブラウザーGUIでパフォーマンス分析がほぼ完結できるようになったことです。従来のパフォーマンスデータ分析でも詳細なパフォーマンスデータは取得されていしましたが、それをグラフ化して利用するためにはマニュアルでパフォーマンスデータのカラム項目を確認し、SQLなどで必要なレポートを作成するプログラミングが必要でした。新しいパフォーマンス分析ツールの使い方を以下でご説明しましょう。
IBM i パフォーマンス分析の実行手順 Performance Data Investigator
IBM i のブラウザーGUIによるパフォーマンス分析(Performance Data Investigator)は以下の手順で実施します。
- サービスでパフォーマンスデータを取得します。
- 収集サービスで取得したデータ(*MGTCOLオブジェクト)からパフォーマンス分析用のPF(テーブル)を作成します。CRTPFRDTA コマンドを実行します。
- Navigator for i のメニューのパフォーマンスからパフォーマンス分析を実行します。
1. 収集サービスでパフォーマンスデータを取得します
1. 収集サービスでパフォーマンスデータを取得します ブラウザーでHTTP://システム名:2001 Navigator for iにログインします。 パフォーマンス → 収集の管理 → 収集サービスの構成 を開きます。
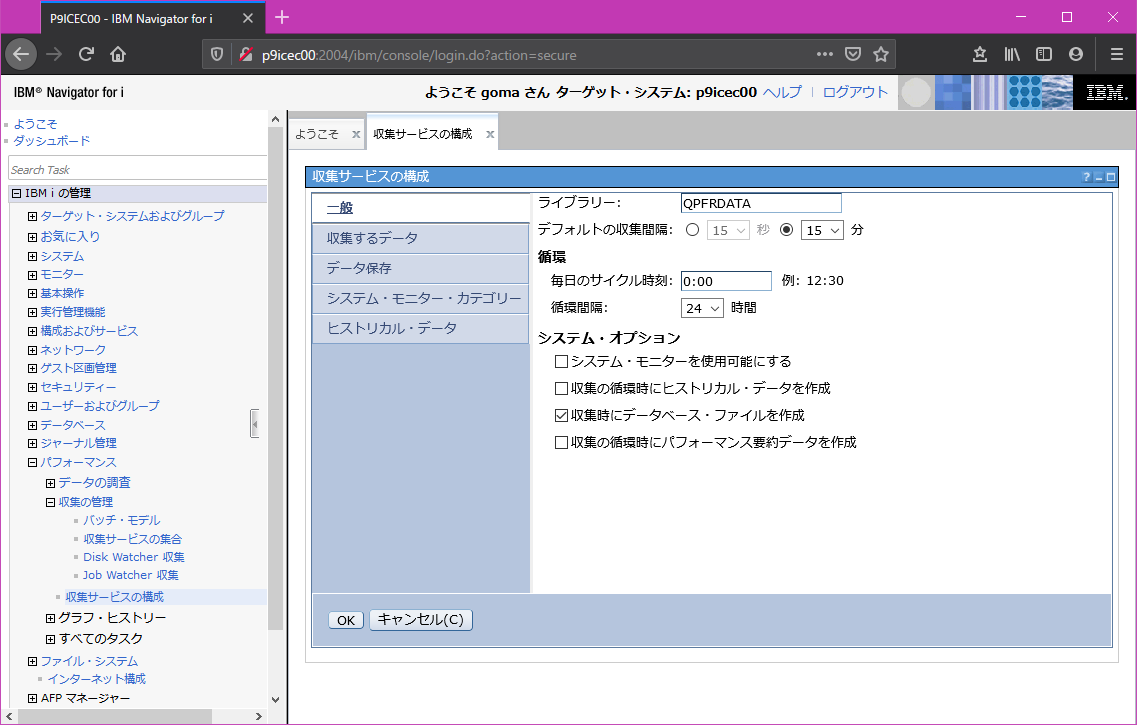
一般タブで以下を設定します。
ライブラリー:収集データを保管するライブラリーを指定
デフォルトの収集間隔:一般的には5分程度が推奨です。
上記以外については必要に応じて変更してください。たとえばデータはデフォルトでは最新の5日間が保持されますが データ保存タブから設定変更できます。パフォーマンスデータを取得するシステムと別なシステムでパフォーマンスデータを分析したい場合、このライブラリーを保管・復元すれば可能です。
2. CRTPFRDTAコマンドで収集サービス取得データ(*MGTCOLオブジェクト)からパフォーマンス分析用のPF(テーブル)を作成します。
CRTPFRDTA FROMMGTCOL(*SELECT) TOLIB(PFRDATA_PF) のように実行します。PFRDATA_PFがパフォーマンス分析用のPFを格納するライブラリーです。(事前にCRTLIBコマンドで作成しておきます)
上記を実行すると下記のようなプロンプトが表示され、*MGTCOLのメンバー名を指定できます。複数の*MGTCOLがある場合は同じ処理を繰り返します。

3. Navigator for i のメニューのパフォーマンスからパフォーマンス分析を実施
Navigator for iで パフォーマンス → データの調査 を開きます。
収集ライブラリー で2で分析用PFを作成したライブラリーを選択します。例ではPFRDATA_PFを選択します。

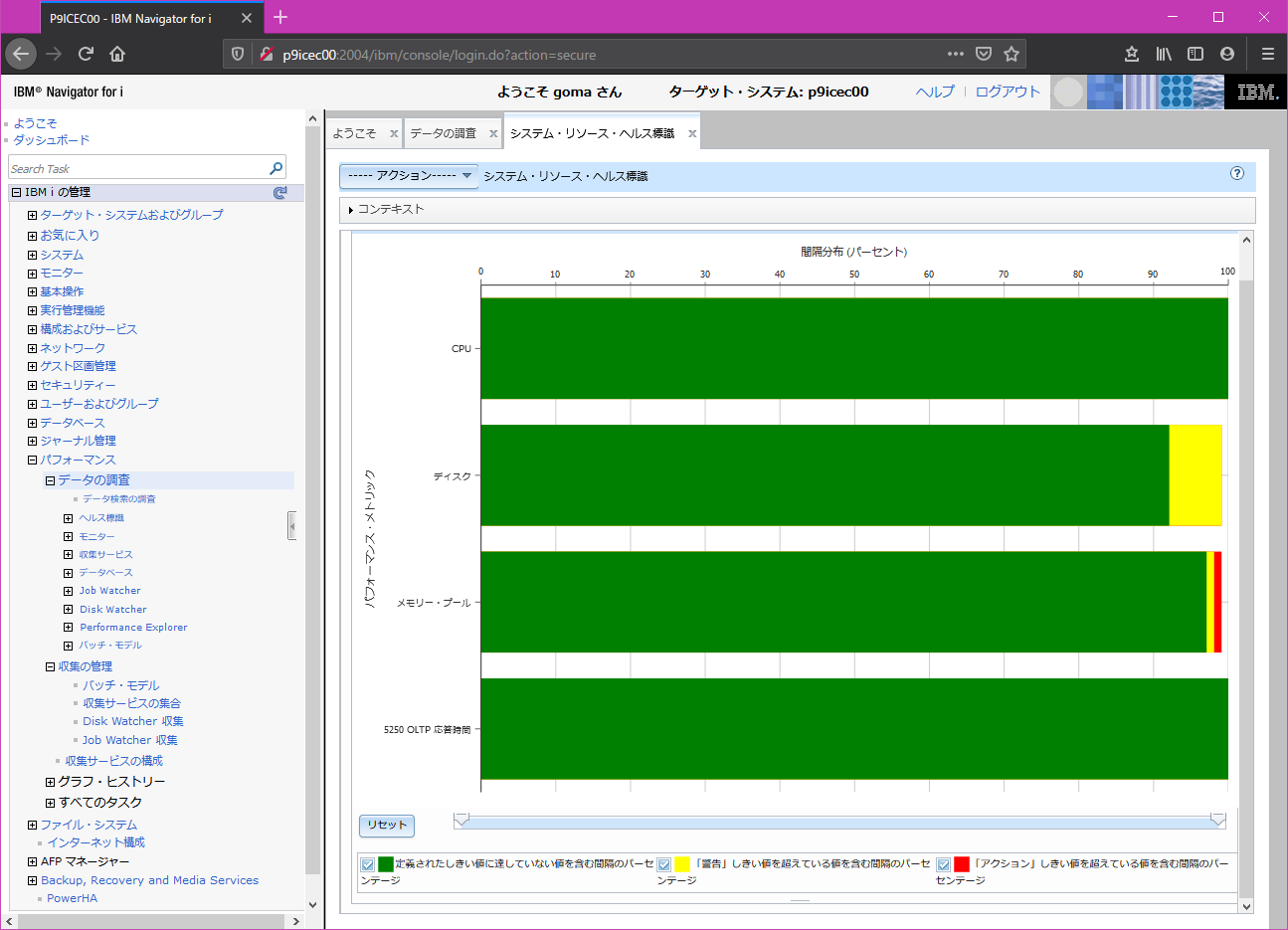
続けてヘルス・標識をクリックし、 Dojoグラフの表示をクリックします。
複数の日付のデータがある場合などは、収集名 から日付を変更してグラフ表示できます。

下記の例ではディスク、メモリーで標準的な閾値を超えるデータが観測されたことが一瞥でわかります。
以下ではよく使用されるグラフをいくつかご紹介します。
CPU使用率および待機の概要
折れ線グラフでCPU使用率が表示されます。左のX軸にはCPU時間が表示されますがこの時間はSMTも考慮した時間になっています。棒グラフは処理時間の内訳でディスパッチされたCPU時間(正味のCPUプロセッシングの時間)やディスク時間、オペレーティングシステム競合時間(シーズロック)、ロック競合時間、不適格待機時間などが表示され、各々時間帯で全体概要としてどのような傾向であったか把握できます。ここから特定の事象に着目して(例えばロック競合が多い時間帯、やディスク時間が長い時間帯、など)分析を深堀するためのヒントとなります。

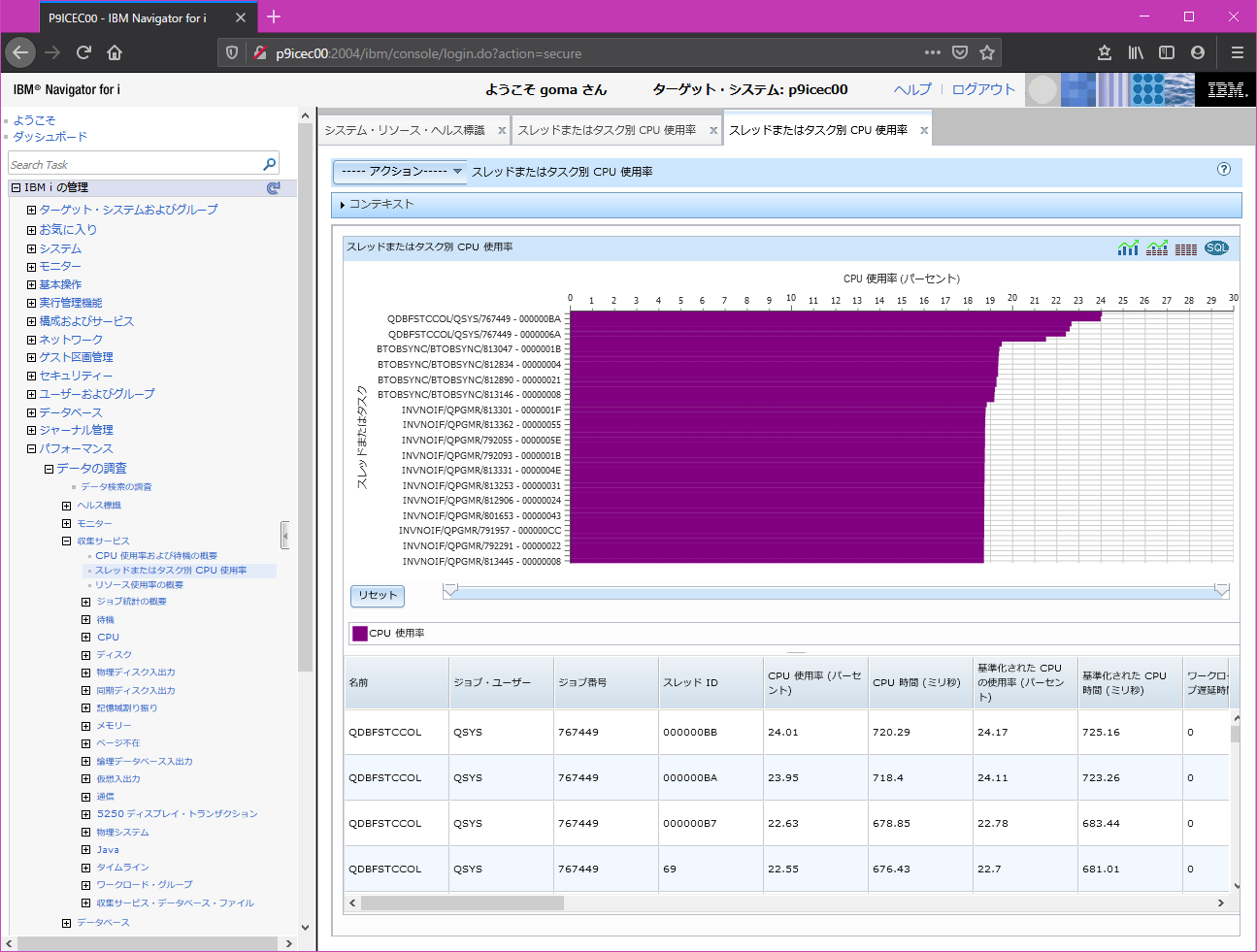
スレッドまたはタスク別CPU時間
明細スレッド、タスクごとでCPU使用率の高いものからリストします。グラフ右上のアイコンをクリックするとグラフのみ・グラフと数値・数値のみ、のように表示が切り替わります。
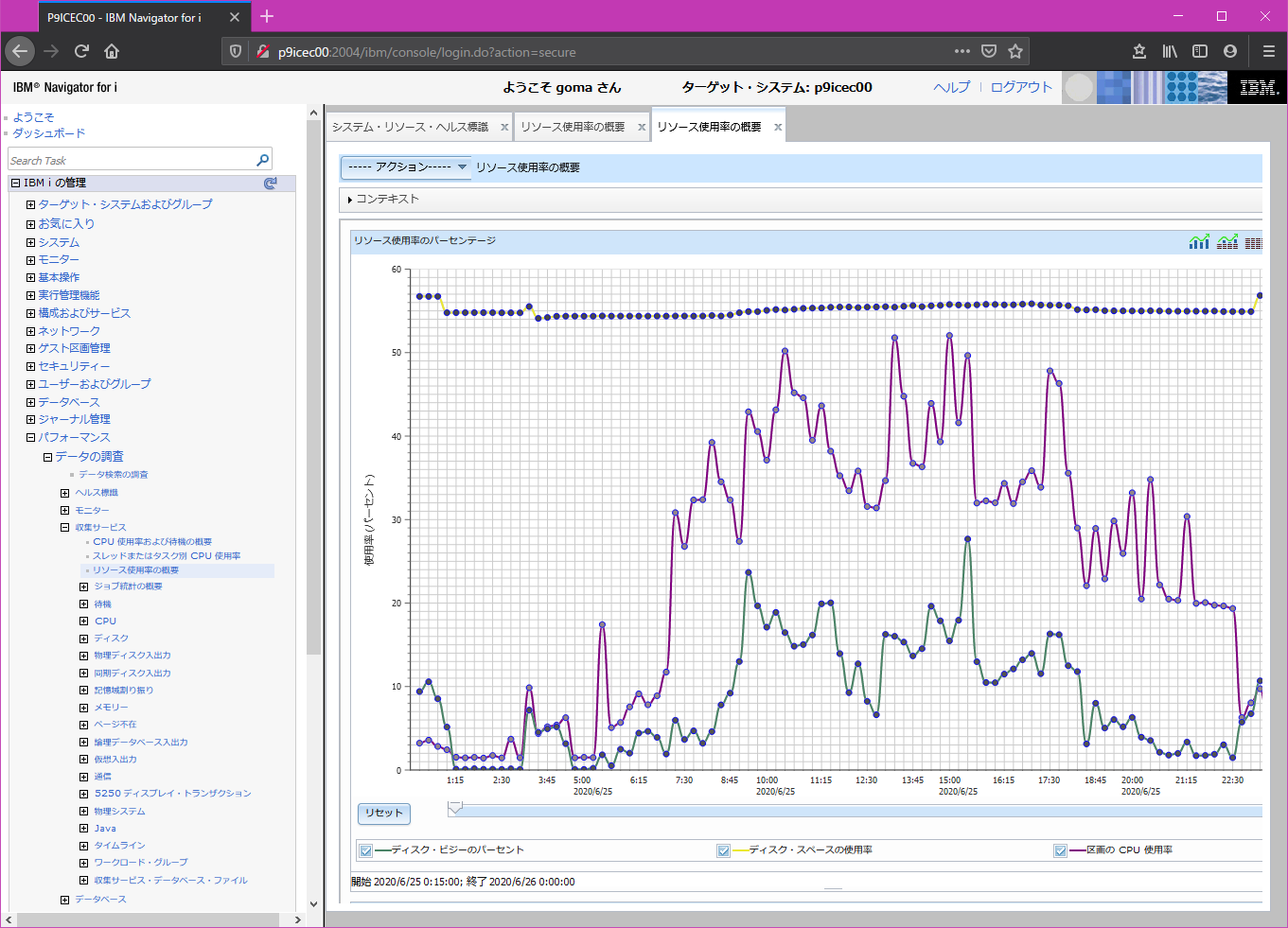
リソース使用率の概要
CPU、メモリ、ディスクの概要がグラフ表示されます。
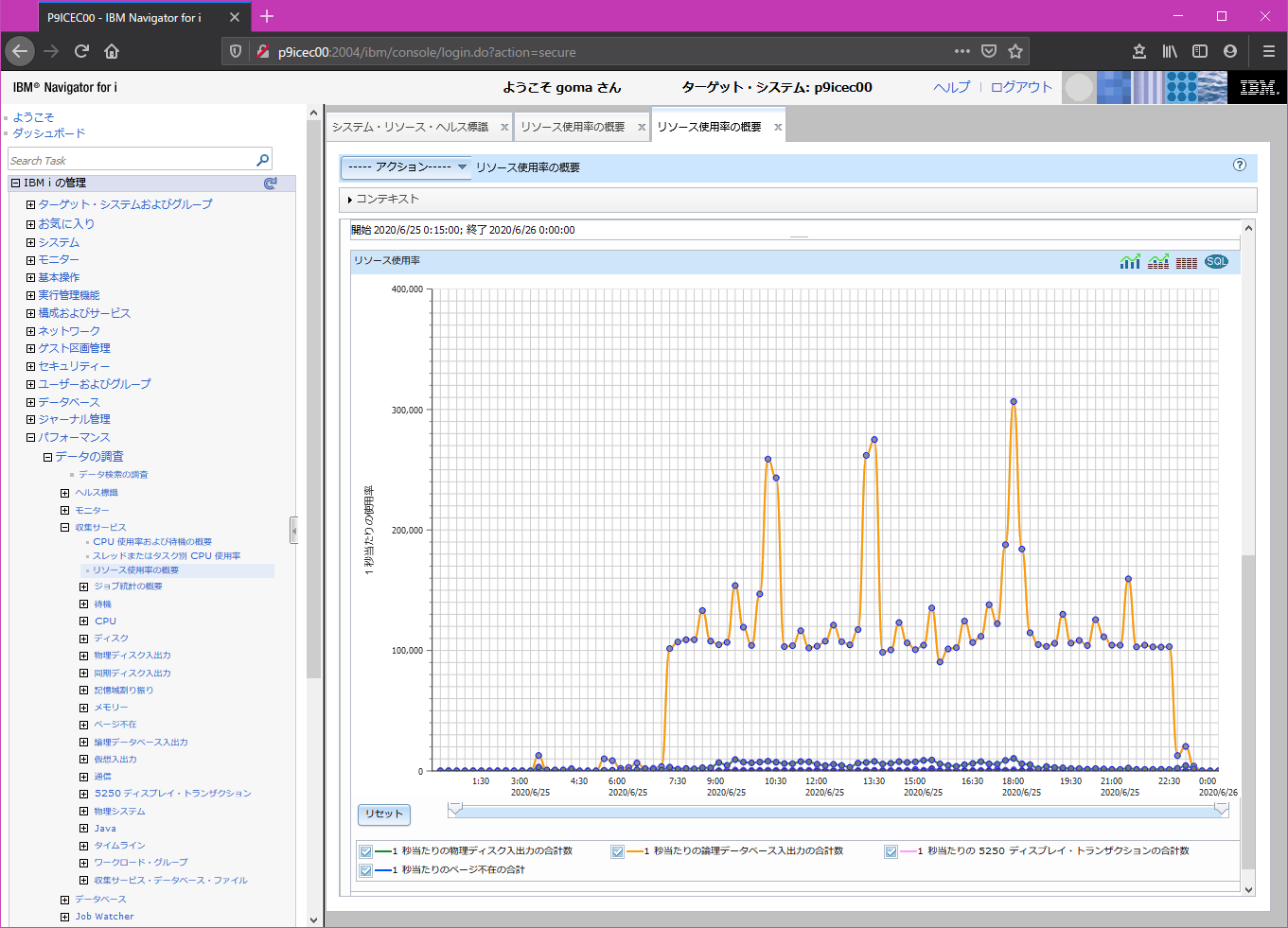
別表で詳細情報も表示されます。(秒あたり物理入出力数、論理DB入出力など)
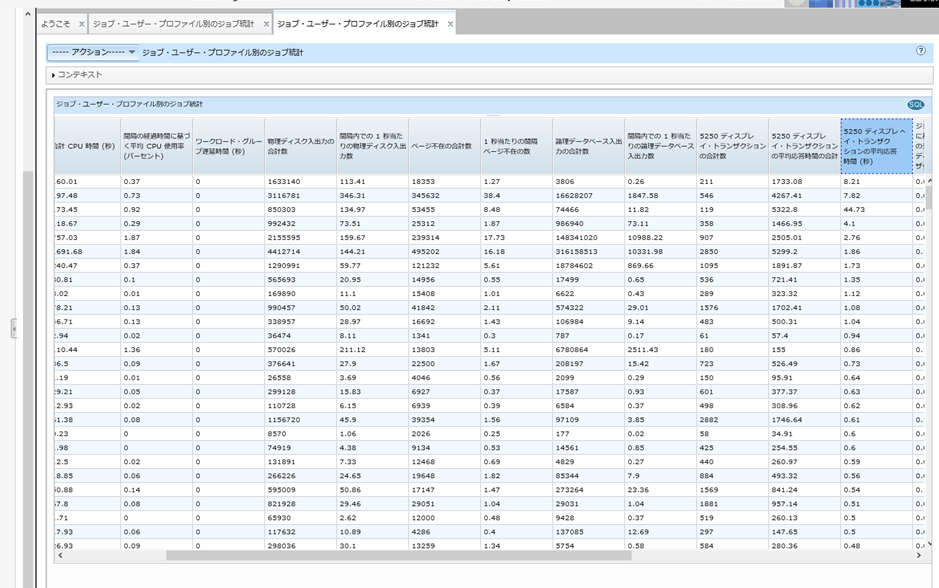
ジョブまたはタスク別のジョブ統計
各ジョブ毎の詳細な処理データが表示されます。

下記の図はユーザープロフィールごとに使用したCPU、メモリ、ディスク使用率等を表示しています。強調表示している 5250の平均応答時間をクリックすると昇順・降順でソート表示できます。
以上ご紹介した以外にも様々なグラフが標準提供されています。一例を以下に示します。
以上のように以前はエキスパートがマニュアルを駆使して作成していたグラフがワンクリックで表示分析が可能となっています。ぜひ最新のIBM i パフォーマンス分析ツールを試してみてください。










